AIGC 舆情数据指南
本文档描述了如何利用 AIGC 的 REST接口 将舆情数据添加到 LLM 引擎,从而让 LLM 对指定的舆情数据进行分析并给出分析报告。
目前 Cube + Baize 的舆情功能定位是对已有舆情数据的 AIGC 处理,帮助开发者分类舆情数据、生成舆情分析结果、生成实时舆情信息图表等功能。系统本身不提供采集舆情数据的功能。
功能描述
通过 LLM 提取数据和数据序列
通过 LLM 实现舆情正负面数据提取
生成舆情策略
生成舆情报告
工作原理
Cube 的舆情数据分析采用关系型数据库进行存储,通过原子数据描述为结构化的图表序列数据进行展示,利用 LLM 对基础数据的正面、负面及中性评价进行筛选、评价和总结。各个模块的关系结构如下图所示:
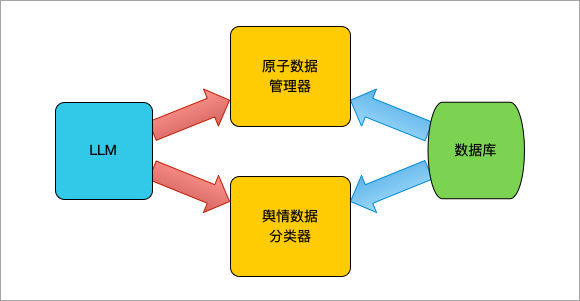
舆情数据工作结构图
原子数据管理器是 Cube 用于管理基础数据 Atom 数据的模块,每个 Atom 数据是可管理的最小数据单位,包括了数据标签、数据日期(年,月,日)和数据值。
数据标签 - 数据标签是用于匹配对话中提示词的关键描述。使用半角逗号(
,)进行分隔。数据日期 - 数据日期使用字符串形式进行描述,例如:
2023年,6月,20日等。对于舆情数据建议按照“日”为单位,连续地添加到数据库中。数据值 - 对应日期的数据值。整数类型。
舆情数据分类器是对采集到的舆情数据进行分类整理,一般的,对于已有舆情系统的场景里,在向 Cube 准备数据时不需要使用分类器。 因为绝大多数情况,舆情的正负面等信息是在舆情系统里处理的,但是我们依然提供了对数据的处理能力。
API 指南
图表数据
操作图表数据的 API文档 参考该链接。
插入数据
action 设置为
"insertAtoms"
删除数据
action 设置为
"deleteAtoms"
具体的数据操作查询 API 文档即可。这里重点介绍一下数据标签的设置方式。
数据标签是生成图表数据的关键,采用字符串形式,使用半角逗号作为分隔符,例如: 时信魔方,舆情,监测,总数,总篇数 , 气温,北京,天气,最低气温 。
示例里分别使用了5个词和4个词描述该条目数据,标签遵循以下基本规则:
使用半角逗号(
,)分隔词组最少 3 个词
第一个词和第二个词组合成图表标题的开头
最后一个词作为数据序列的图例说明
上述示例生成的图表标题分别是: 时信魔方-舆情 - ... 和 气温-北京 - ... ,数据图例名称分别是: 总篇数 和 最低气温 。
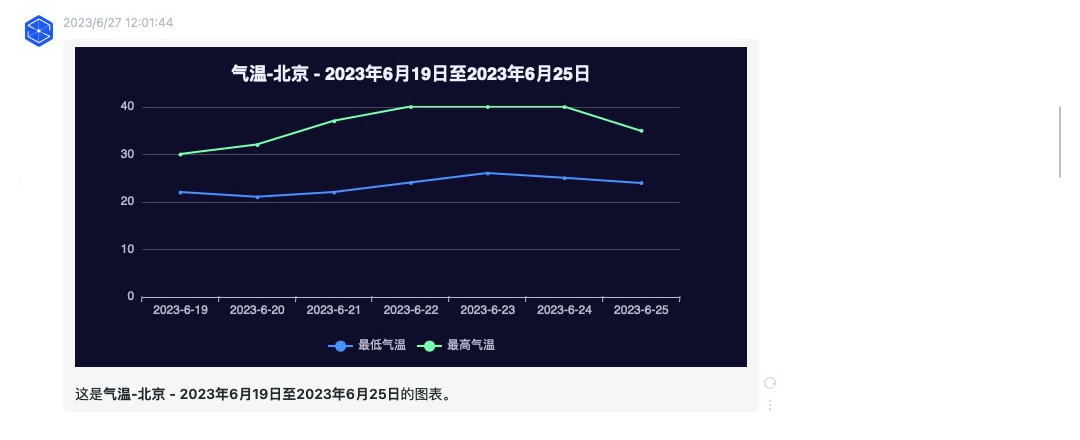
图表示例
舆情正负面分析
Cube 的舆情模块使用复合上下文 ComplexContext 的异步推理接口对舆情内容进行正负面分析。开发者通过 舆情数据接口 向 Cube 导入舆情相关数据,例如相关的舆情正面、负面文章等。Baize LLM 会自动对舆情文章内容进行相关的正面和负面分析,开发者通过 获取上下文推理内容 接口以异步方式获取分析内容。

推理内容示例
通过以下步骤实现对正负面数据的推理:
添加正负面文章,以便在进行互动对话时,Baize 能找到对应时间的相关文章数据。
调用
addArticle新增文章数据时, 我们建议category使用有显著辨识度的名词,例如上述示例category设置为 汤臣倍健 。调用互动对话接口后,判断
context的inferable值,如果该值为true,则调用 获取上下文推理内容 获取inferenceResult数据,从而得到推理结果。
提示词设计
在使用互动对话方式获取舆情数据时,提示词可以简单明了,即使用较短的提示词 Baize 就能进行数据匹配并生成数据序列和推理。
例如:
展示汤臣倍健2023年6月的舆情数据图表。
在实际的应用场景里,我们需要在提示词里明确数据的时间描述,例如: 2023年6月 。在时间不明确的情况下 Baize 会尝试推理最近的数据日期。对于不符合日期的数据 Baize 不会进行后续推理。